
Simmy, the monkey for making chaos

This is a cross-post from elvanydev.com.
What Is Simmy?
Simmy is a chaos-engineering and fault-injection tool based on the idea of the Netflix Simian Army, integrating with the Polly resilience project for .NET, Simmy takes advantage of the power of Polly to help you to answer these questions:
- Is my system resilient enough?
- Am I handling the right exceptions/scenarios?
- How will my system behave if X happens?
- How can I test my resilience, without waiting for a handled (or even unhandled) exception to happen in my production environment?
Why "Simmy"?
It's an analogy with Simian, rhyme with Polly and also give us the idea that the library Simulates faults.

So, Simmy is a pirate monkey, like Jack the monkey from Pirates of the Caribbean, it's unstoppable!
What is Chaos Engineering?
Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Given that distributed architectures nowadays leverage the most critical systems and most popular applications which we use every day, the chaos engineering and its principles have become in an important matter, so much so that it's considered as a discipline and I'd say that for almost every SRE team out there, being aware of those principles is a must when it comes to truly guarantee the resilience and reliability of the systems.
As I mentioned earlier, Netflix is one of the most important contributors in the matter with its Simian Army project which in a nutshell, is a framework to inject faults randomly in a production environment, such as stop instances, introduce latency or even simulates an outage of an entire availability zone allowing you to detect abnormal conditions and test the ability to survive them.
Another interesting project is Waterbear from LinkedIn, which offers tools pretty similar than the Simian Army, but also things like simulate network, disk, CPU and memory failures, DNS pollution, Rack fails, etc. There are also a lot of resources and tools out there that you can find very useful and compatible with the main cloud providers.
How Simmy works?
As I said earlier, Simmy is based on Polly, so at the end of the day the building block of this little simian are the policies as well, which we've called Monkey Policies (or chaos policies), which means, as well as a Policy is the minimum unit of resilience for Polly, a MonkeyPolicy is the minimum unit of chaos for Simmy.
In other words, Simmy allows you to introduce a chaos-injection policy (Monkey Policy) or policies at any location where you execute code through Polly. So, for now, Simmy offers three chaos policies:
- Fault: Injects exceptions or substitute results, to fake faults in your system.
- Latency: Injects latency into executions before the calls are made.
- Behavior: Allows you to inject any extra behaviour, before a call is placed.
All chaos policies (Monkey policies) are designed to inject behavior randomly (faults, latency or custom behavior), so a Monkey policy allows you to specify an injection rate between 0 and 1 (0-100%) thus, the higher is the injection rate the higher is the probability to inject them. Also it allows you to specify whether or not the random injection is enabled, that way you can release/hold (turn on/off) the monkeys regardless of injection rate you specify, it means, if you specify an injection rate of 100% but you tell to the policy that the random injection is disabled, it will do nothing.
How can Simmy help me out?
It's well known that Polly helps us a ton to introduce resilience to our system making it more reliable, but I don't want to have to wait for expected or even unexpected failures to test it out. My resilience could be wrongly implemented because most of the time we handle transient errors, which is totally fine, but let's be honest, how many times we've seen those errors while we develop/debug? then how are we making sure that the behavior after those kinds of errors is the one that we expect? through the unit test, hopefully? so, are unit tests enough to make sure that the whole workflow is working fine and the underlying chain of calls/dependencies are going to degrade gracefully? Also, testing all the scenarios or mocking failure of some dependencies is not straight forward, for example, a cloud SaaS or PaaS service.
So, how can Simmy help us to make sure that we’re doing our resilience strategies right? the answer is too simple: making chaos! by simulating adverse conditions in our environments (ideally in environments different than development) and watching how our system behaves under those conditions without making assumptions, that way, we're going to realize if our resilience strategies are well implemented thus, we'll find out if our system is capable to withstand chaotic conditions.
Using Simmy, we can easily make things that usually aren't straight forward to do, such as:
- Mock failures of dependencies (any service dependency for example).
- Define when to fail based on some external factors - maybe global configuration or some rule.
- A way to revert easily, to control the blast radius.
- Production grade, to run this in a production or near-production system with automation.
No more introduction, let's see Simmy in action!
Hands-on Lab
In order to stay this handy and funny as possible, let's base on the DUber problem and solution which is, as you know, a distributed architecture based on microservices using .Net Core, Docker, Azure Service Fabric, etc that I previously walked you through four posts.
The example
We're going to see an example/approach of how to use Simmy in a kind of real but simple scenario over a distributed architecture to inject chaos in our system in a configurable and automatic way.
So, we're going to demonstrate the following patterns with Simmy:
- Configuring StartUp so that Simmy chaos policies are only introduced in builds for certain environments.
- Configuring Simmy chaos policies to be injected into the app without changing any code, using a UI/API to update/get the chaos configuration.
- Injecting faults or chaos automatically by using a WatchMonkey specifying a frequency and duration of the chaos.
I based myself on the great Dylan's example in order to configure Simmy chaos policies on StartUp, however, there are significant differences that I’ll explain later.
The Architecture
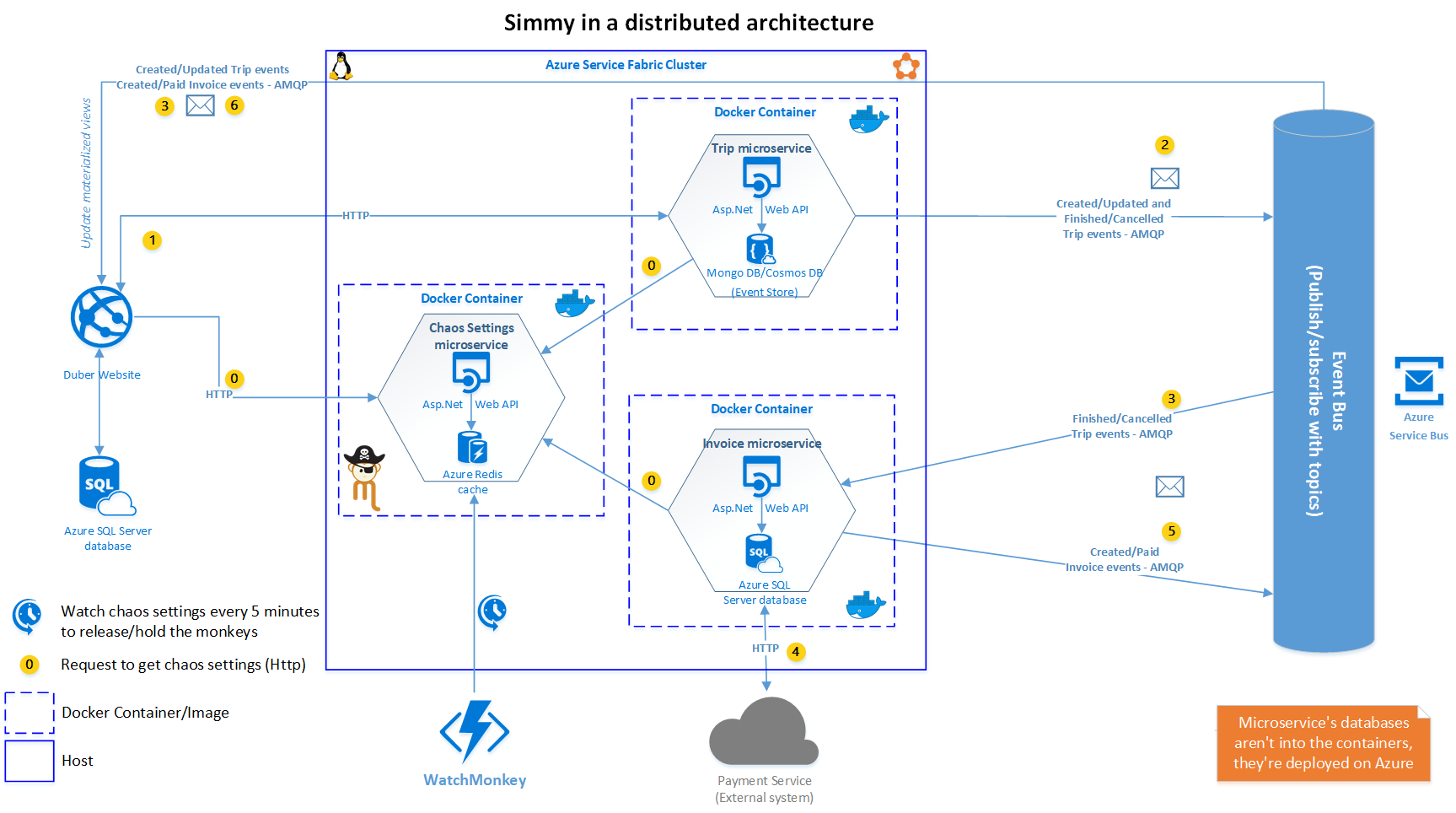
As you can see, there are a couple of new components in the architecture (respect to the old one), let's see:
Chaos Settings Microservice
It's a Web API which takes care of to store and get the chaos settings using Azure Redis Cache as a repository. This is one of the main differences I mentioned earlier; instead of using IOptionsSnapshot<> to get the chaos settings, we're getting the settings from the API, which is more convenient in a distributed architecture where you have deployed your services in a cluster over dozens, hundreds or even thousands of instances of your services, so in that case it's not suitable/easy just changing the appsettings file in every instance deployed.
WatchMonkey
Is an Azure Function with a timer trigger which is executed every 5 minutes (value set arbitrarily for this example) in order to watch the monkeys (chaos settings/policies) set up trhough the chaos UI. So, if the automatic chaos injection is enabled it releases all the monkeys for the given frequency within the time window configured (Max Duration), after that time window all the monkeys are caged (disabled) again. It also watches monkeys with a specific duration, allowing you to disable specific faults in a smaller time window.
You can find the whole explanation about DUber architecture here.
The Chaos UI
Is the monkeys administrator, which allows us to set up the general chaos settings and also settings at operation level. The UI uses the Chaos Settings API to store and get the settings.
General Chaos Settings
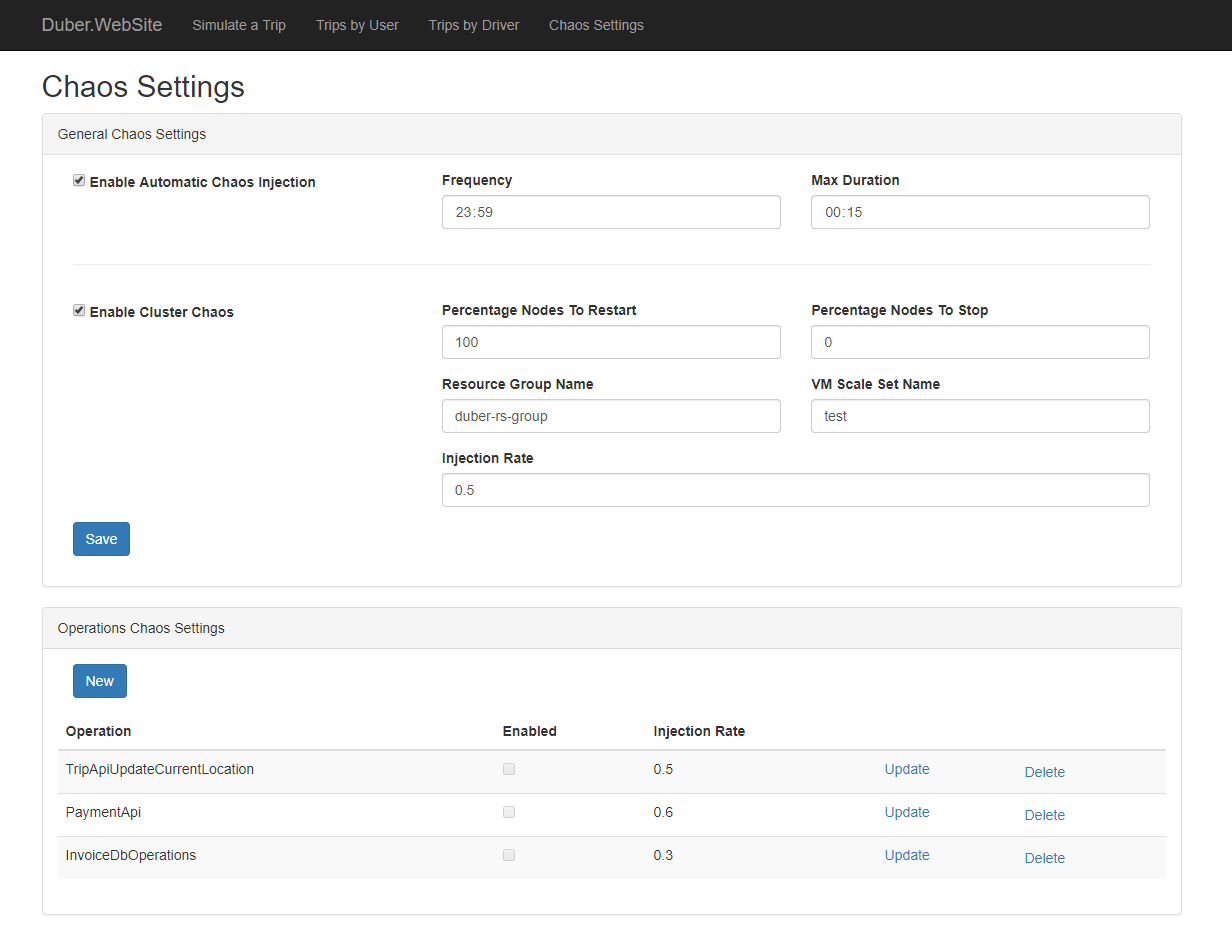
Enable Automatic Chaos Injection: Allows you to inject the chaos automatically based on a frequency and maximum chaos time duration. Which means in the given example, that the chaos will be enabled every day (every 23:59 hours) and it will take 15 minutes.
Frequency:
A Timespan indicating how often the chaos should be injected.
Max Duration:
A Timespan indicating how long the chaos should take once is injected.
Enable Cluster Chaos:
Allows you to inject chaos at cluster level. (You will need to create a service principal, then set up the values for GeneralChaosSetting section into the appsettings file of Duber.Chaos.API project, or their respective environment variables inside docker-compose.override. You might consider storing these secrets into an Azure Key Vault)
Percentage Nodes to Restart:
An int between 0 and 100, indicating the percentage of nodes that should be restarted if cluster chaos is enabled.
Percentage Nodes to Stop:
An int between 0 and 100, indicating the percentage of nodes that should be stopped if cluster chaos is enabled.
Resource Group Name: The name of the resource group where the VM Scale Set of the cluster belongs to.
VM Scale Set Name: The name of the Virtual Machine Scale Set used by the cluster.
Injection Rate:
A double between 0 and 1, indicating what proportion of calls should be subject to failure-injection. For example, if 0.2, twenty percent of calls will be randomly affected; if 0.01, one percent of calls; if 1, all calls.
Operations Chaos Settings
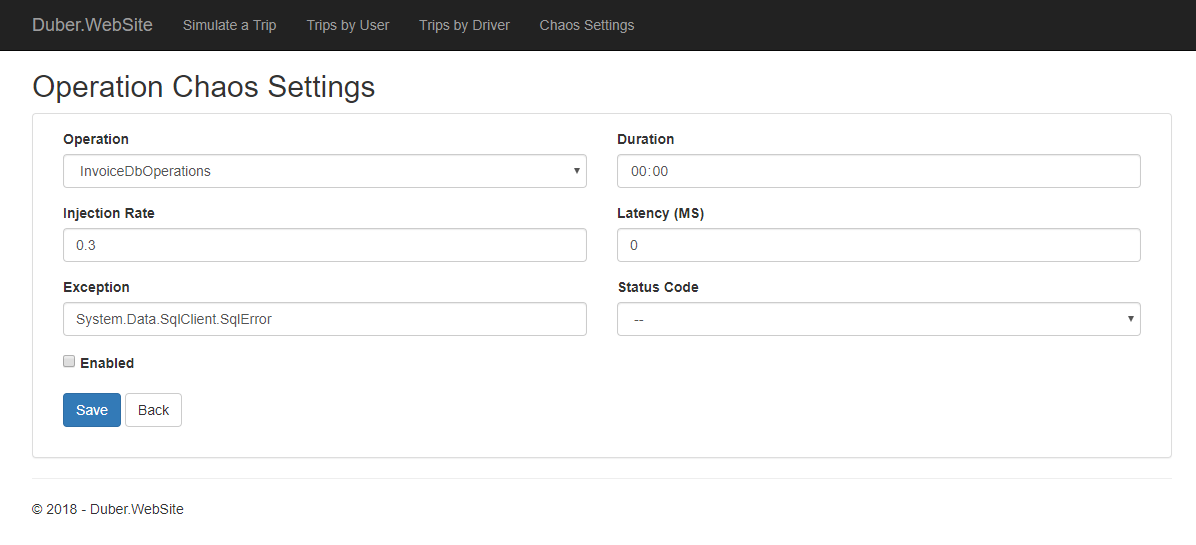
Operation: Which operation within the app these chaos settings apply to. Each call site in your codebase which uses Polly and Simmy can be tagged with an OperationKey. This is simply a string tag you choose, to identify different call paths in your app, in our case, we're using an enumeration located in the Shared Kernel project, where we've defined (arbitrarily) some operations to inject them some chaos.
Duration:
A Timespan indicating how long the chaos for a specific operation should take once is injected if Automatic Chaos Injection is enabled. (Optional) Should be less than the value configured for MaxDuration.
Injection Rate:
A double between 0 and 1, indicating what proportion of calls should be subject to failure-injection. For example, if 0.2, twenty percent of calls will be randomly affected; if 0.01, one percent of calls; if 1, all calls.
Latency: If set, this much extra latency in ms will be added to affected calls, before the http request is made.
Exception: If set, affected calls will throw the given exception. (The original outbound http/sql/whatever call will not be placed.)
Status Code: If set, a result with the given http status code will be returned for affected calls. (The original outbound http call will not be placed.)
Enabled: A master switch for this call site. When true, faults may be injected at this call site per the other parameters; when false, no faults will be injected.
How the chaos is injected?
The best way to build robust resilience strategies using Polly is through the PolicyWrap, which at the end of the day makes up a set of policies working together as a single policy. So, the recommended way for introducing Simmy is to use one or more Monkey Policies as the innermost policies in the PolicyWrap. That way, they alter the usual outbound call at the last minute, substituting their fault, adding a custom behavior or adding extra latency allowing us to test our resilience strategies and see how we're handling the chaos/faults injected by Simmy.
One of the simplest ways to add chaos-injection all across your app without changing existing configuration code is taking advantage of PolicyRegistry by storing all policies of each strategy in their respective registry (you might have several strategies with different policies to handle different scenarios, thus different PolicyRegistry's).
So, in order to do that, we're going to add some code in StartUp class.
First of all, we need to add our resilience strategies, then we're going to inject them chaos policies (monkeys). For Http calls, we're going to build a strategy on the fly, but for SQL Azure database calls we're going to use our SqlPolicyBuilder which we've made previously because the idea is to reuse our resilience strategies!
Setting up our Http resilience strategy
var policyRegistry = services.AddPolicyRegistry();
policyRegistry["ResiliencePolicy"] = GetHttpResiliencePolicy();
services.AddHttpClient<ResilientHttpClient>()
.AddPolicyHandlerFromRegistry("ResiliencePolicy");
Setting up our SQL Azure DB strategy
services.AddSingleton<IPolicyAsyncExecutor>(sp =>
{
var sqlPolicyBuilder = new SqlPolicyBuilder();
return sqlPolicyBuilder
.UseAsyncExecutor()
.WithDefaultPolicies()
.Build();
});
Injecting chaos policies (monkeys) to our resilient strategies
We're injecting the monkeys only in environments different than Development (which is the usual, but it's up to you, even you might make it configurable through the Chaos UI as well) through the AddChaosInjectors/AddHttpChaosInjectors extension methods on IPolicyRegistry<> which simply takes every policy in our PolicyRegistry and wraps Simmy policies (as the innermost policy) inside.
if (env.IsDevelopment() == false)
{
// injects chaos to our Http policies defined previously.
var httpPolicyRegistry = app.ApplicationServices.GetRequiredService<IPolicyRegistry<string>>();
httpPolicyRegistry?.AddHttpChaosInjectors();
// injects chaos to our Sql policies defined previously.
var sqlPolicyExecutor = app.ApplicationServices.GetRequiredService<IPolicyAsyncExecutor>();
sqlPolicyExecutor?.PolicyRegistry?.AddChaosInjectors();
}
public static IPolicyRegistry<string> AddHttpChaosInjectors(this IPolicyRegistry<string> registry)
{
foreach (var policyEntry in registry)
{
if (policyEntry.Value is IAsyncPolicy<HttpResponseMessage> policy)
{
registry[policyEntry.Key] = policy
.WrapAsync(MonkeyPolicy.InjectFaultAsync<HttpResponseMessage>(
(ctx, ct) => GetException(ctx, ct),
GetInjectionRate,
GetEnabled))
.WrapAsync(MonkeyPolicy.InjectFaultAsync<HttpResponseMessage>(
(ctx, ct) => GetHttpResponseMessage(ctx, ct),
GetInjectionRate,
GetHttpResponseEnabled))
.WrapAsync(MonkeyPolicy.InjectLatencyAsync<HttpResponseMessage>(
GetLatency,
GetInjectionRate,
GetEnabled))
.WrapAsync(MonkeyPolicy.InjectBehaviourAsync<HttpResponseMessage>(
(ctx, ct) => RestartNodes(ctx, ct),
GetClusterChaosInjectionRate,
GetClusterChaosEnabled))
.WrapAsync(MonkeyPolicy.InjectBehaviourAsync<HttpResponseMessage>(
(ctx, ct) => StopNodes(ctx, ct),
GetClusterChaosInjectionRate,
GetClusterChaosEnabled));
}
}
return registry;
}
This allows us to inject Simmy into our app without changing any of our existing app configuration of Polly policies. These extension methods configure the policies in the PolicyRegistry with Simmy policies which react to chaos configured through the UI getting that configuration from Polly Context at runtime taking advantage of the power of the contextual configuration.
Notice that we're using the InjectFaultAsync monkey policy not only to inject an Exception but to inject a HttpResponseMessage. Also, we're using the InjectBehaviourAsync monkey to inject the custom behavior which takes care of to restart/stop instances in our cluster.
How does it get the chaos settings?
We're injecting a factory which takes care of getting the current chaos settings from the Chaos API. So we're injecting the factory as a Lazy Task Scoped service because we want to avoid to add additional overhead/latency to our system, that way we only retrieve the configuration once per request no matter how many times the factory is executed.
Injecting chaos settings factory
public static IServiceCollection AddChaosApiHttpClient(this IServiceCollection services, IConfiguration configuration)
{
services.AddHttpClient<ChaosApiHttpClient>(client =>
{
client.Timeout = TimeSpan.FromSeconds(5);
client.BaseAddress = new Uri(configuration.GetValue<string>("ChaosApiSettings:BaseUrl"));
});
services.AddScoped<Lazy<Task<GeneralChaosSetting>>>(sp =>
{
// we use LazyThreadSafetyMode.None in order to avoid locking.
var chaosApiHttpClient = sp.GetRequiredService<ChaosApiHttpClient>();
return new Lazy<Task<GeneralChaosSetting>>(() => chaosApiHttpClient.GetGeneralChaosSettings(), LazyThreadSafetyMode.None);
});
return services;
}
Using chaos settings factory from consumers
So, wherever we want to make the chaos to be injected inside of the workflow of our application using Polly and Simmy (and also using this approach), the only thing we need to do (after setting up the resilience strategies and monkeys, of course) is tagging the executions through the OperationKey as we explained before and storing the chaos settings inside the Context using the WithChaosSettings extension method, that way, the chaos might or might not be injected at runtime contextually.
// constructor
public TripController(Lazy<Task<GeneralChaosSetting>> generalChaosSettingFactory,...)
{
...
}
public async Task<IActionResult> SimulateTrip(TripRequestModel model)
{
...
generalChaosSetting = await _generalChaosSettingFactory.Value;
var context = new Context(OperationKeys.TripApiCreate.ToString()).WithChaosSettings(generalChaosSetting);
var response = await _httpClient.SendAsync(request, context);
...
}
private async Task UpdateTripLocation(Guid tripId, LocationModel location)
{
...
generalChaosSetting = await _generalChaosSettingFactory.Value;
var context = new Context(OperationKeys.TripApiUpdateCurrentLocation.ToString()).WithChaosSettings(generalChaosSetting);
var response = await _httpClient.SendAsync(request, context);
...
}
Putting all together
In this example, we're injecting the monkey policies at different layers such as Application, Data and the Anti Corruption Layer. (which at the end of the day, it is executed in the Application layer) In the case of the Application layer, we're tagging all the operations related with the simulation of a trip into the website's Trip controller.
On the other hand, we're tagging the call to the Payment service which is an external system, that's why that guy lives in our ACL (Anti Corruption Layer). So, being able to inject chaos here is pretty interesting, because it's an external dependency which we don't have control on, so we might want to simulate how our system behaves when that service returns a BadRequest, InternalServelError, etc.
In the case of the Data layer, we're injecting the chaos at general level by tagging all the operations of the InvoiceContext with the same tag. This allows us to test the resilience of our system at different layers but also as granular or as general as we want. So, we can see how the system behaves if there's an error in the database and how the downstream calls like the repository, controller, etc are degraded.
At the end of the day is up to you where you want to make possible the chaos to be injected, it depends on whatever makes more sense to you given your resilience strategies, for example, in our case, given that we have a strategy for SQL executions, it might be interesting to inject some chaos on the ReportingRepository as well, to see how's the behavior when there's an error when it's updating the materialized view, because if we're not handling the errors properly there, we might lose the messages from the message bus, and that's not good.
Considerations
- You might want to consider making the Chaos UI in a separated project, in our case it's housed into
Duber.WebSitejust for the example purposes, but that's usually an internal tool mostly for the SRE team. - You might want to deploy the Chaos Settings API outside of the cluster in order to avoid it will be affected when you release the cluster chaos.
- You'll need to secure the Chaos Settings API properly.
- The cluster chaos does not depend on a specific operation, so when it's enabled the monkey will be released by the first policy executed, configured previously in our workflow, it means that in our case might be, simulating a trip, creating an invoice or performing the payment. (you could inject it at operation level as well if you want to)
- The chaos cluster may also introduce extra latency since we're using Azure REST API to restart/stop nodes in our cluster. So we need a request to get the token (that's why we need a Service Principal) and a couple of requests more to get the VM's then restart/stop them.
- We choose Azure Cache for Redis to store the chaos settings because of the high performance we need here since we need to get the settings in every request and we don't want to add extra overhead and latency to our system. (We might consider using data persistence)
Wrapping up
We’ve seen how important is nowadays the chaos engineering and the power of Polly and Simmy working together to meet its principles, and how they can help us to make sure that our resilience strategies are working fine and we’re truly offering a highly available and reliable service injecting the chaos to our system without changing existing configuration code and in an automatic way to enable making chaos periodically, allowing us to test our system in production environment under chaotic conditions, using chaos policies such as Fault, Latency and Behavior.
The approach we've proposed here has pros and cons (like everything), for instance, one of the biggest advantages of having a Chaos API is that it allows us to automate the chaos injection not only through the WatchMonkey but after a deployment, we might use an Azure DevOps Gate to enable the automatic chaos, then let the WatchMonkey does the dirty work, which is very convenient in order to make sure that our latest releases keep withstanding turbulence conditions in a production environment. Besides the automation, we could take the API to the next level, for example, we can record logs, or whatever metadata to analyze them and make further decisions.
On the other hand, one of the disadvantages could be the latency that the Chaos API may introduce to our system since we're going to need an additional request where we're using our Chaos Policies, that's why we need to ensure that the API is going to be highly available and as fast as possible.
Next steps
We need to have in mind that a good chaos engineering tool/strategy also requires a good monitoring tool/strategy to be able to realize easily about system weaknesses and be aware where they are exactly, then be able to make decisions faster to fix them, otherwise it might be painful and harder trying to improve our system however much we have developed a great chaos engineering strategy. So, I'd recommend Application Insights, Azure Monitor, Stackify Retrace, etc.
So, stay tuned because in the next post we'll propose another approach using Azure App Configuration and how it can help us to solve the downside we mentioned before of this current approach about the latency. In the meantime, I encourage you all to start making experiments using Simmy so you can realize by yourself about the power of this little monkey!
Credits!
Simmy was the brainchild of @mebjas and @reisenberger. The major part of the implementation was by @mebjas and myself, with contributions also from @reisenberger of the Polly team. Thanks also to @joelhulen for the amazing work with the logos and the help on admin/DevOps tasks.
Take a look at the whole implementation on my GitHub repo: https://github.com/vany0114/chaos-injection-using-simmy
